Intorno al Villaggio Olimpico
In vista delle Olimpiadi invernali del 2026 verrà costruito un villaggio olimpico nella zona di Porta Romana, un ex scalo ferroviario e area industriale a sud-est del centro di Milano. Dopo i giochi, gli edifici dovrebbero essere convertiti in residenze universitarie. Dato l’impatto che il progetto avrà sull’area, residenti, investitori, osservatori e realtà locali hanno iniziato a discutere dei rischi e delle opportunità.




Analisi e Catalogo
Sono stati identificati 191 post da Facebook riguardanti il progetto (e le relative immagini). Ogni post è stato classificato in base all’autore (ad esempio politici, comunità locali, agenzie immobiliari). Attraverso un algoritmo di intelligenza artificiale, da ogni post sono state estratte le parole chiave, poi categorizzate in base alla tematica. L’analisi mette in relazione le parole chiave e le immagini più usate da ogni tipologia di autore. Il dataset di immagini, autori e parole chiave è raccolto nel catalogo “Oltre i giochi”.

Installazione
Per l’installazione “Intorno al Villaggio Olimpico” sono stati selezionati dal dataset di immagini quattro render del progetto. Le parole chiave più utilizzate da ogni gruppo di utenti sono state inserite in algoritmo di intelligenza artificiale per espandere le immagini. Con questo processo sono state generate otto cornici che è possibile posizionare intorno all’immagine originale per rappresentare come i diversi gruppi immaginano ciò che sta attorno al villaggio olimpico.


Processo di progettazione
Allestimento dell'artefatto
Il layout dell'artefatto è stato progettato per offrire ai visitatori un'esperienza coinvolgente e informativa. Il tavolo, di 130x70 cm, presenta quattro contenitori, ciascuno dedicato a uno dei render selezionati dalla ricerca "Beyond the Games". Ogni contenitore ospita otto cornici, una per ogni categoria di stakeholder, distinguibili grazie alle etichette apposte su ciascuna di esse. Quando vengono estratte dallo stand, i visitatori possono sovrapporre le cornici all'immagine originale fissata sul tavolo, facilitando l'interazione diretta tra l'immagine e le prospettive dei vari stakeholder.
Sul fondo di ogni cornice sono elencate le 10 parole chiave utilizzate dal modello di intelligenza artificiale per elaborare le immagini, offrendo ai visitatori un'ulteriore chiave interpretativa. Per completare l'aspetto grafico della mostra, i visitatori possono trovare: istruzioni per la fruizione della mostra, informazioni specifiche relative alle categorie di stakeholder e il processo seguito per generare i fotogrammi attraverso la manipolazione dei dati e l'intelligenza artificiale. Inoltre, il tavolo include il catalogo "Beyond the Games" contenente i dati collezionati ed esaminati durante la ricerca.
Remix delle parole chiave: prompt per Stable Diffusion
Per rappresentare i dati risultanti dalla ricerca, è stato impiegato Stable Diffusion (SD), un modello avanzato di apprendimento automatico introdotto nel 2022, usato per la manipolazione delle immagini. SD si distingue per la sua capacità di generare immagini dal testo. Per avviare il processo di manipolazione grafica su SD, sono stati formulati prompt specifici basati sulle parole chiave estratte dalla ricerca sopra citata.
Dopo aver identificato le 10 parole chiave più frequenti per ogni categoria di stakeholder, si è proceduto a una categorizzazione in aggettivi e sostantivi. I sostantivi sono stati associati a oggetti concreti da incorporare nella scena generata, mentre gli aggettivi sono stati collegati a variazioni grafiche, come i cambiamenti di colore all'interno dell'immagine.
Successivamente, si è proceduto a una "classificazione" delle parole, raggruppandole in cinque categorie in base al loro significato nel contesto. Queste cinque categorie sono state definite "spirito analitico", "spirito verde", "sponsor", "infrastrutture" e "spirito motivazionale". L'assegnazione delle parole a queste categorie è stata sottoposta a un meticoloso processo di verifica manuale all'interno del dataset, che ha comportato la comprensione del significato del contesto e la successiva assegnazione alla categoria corrispondente.
Nella fase conclusiva, vista l'efficacia maggiore dimostrata da SD con prompt di singole parole, ogni categoria è stata esplicitata attraverso una frase descrittiva che ne chiarisce il significato contestuale. Ad esempio, il termine "cantiere" è stato associato alla categoria "infrastrutture", che racchiude nozioni come "tralicci, impalcature, cesate, lavoratori edili".

Stable Diffusion
Per sfruttare al meglio le funzionalità di Stable Diffusion, abbiamo utilizzato principalmente due estensioni: Control Net, con i modelli annessi e Civit.AI Helper, da cui è stato scaricato il modello Realistic Vision, utilizzato per manipolare le immagini.
La scheda text2img è stata utilizzata per espandere i render originali. Come prompt sono state utilizzate le parole chiave rielaborate come descritto in precedenza e con pesi diversi a seconda della loro frequenza nei post, oltre alle parole chiave "RAW photo, realistic, subject, 8k uhd, dslr, high quality, Fujifilm XT3" per migliorare la qualità finale del render e infine, sempre per migliorare la qualità dell'immagine, sono stati utilizzati i lora add_detail ed Edob Landscape Alpha.

Inoltre, un prompt negativo ("deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, painting, anime, text, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck, distorted") e due negative embeddings, Bad Dream e Unrealistic Dream sono stati utilizzati per evitare allucinazioni.

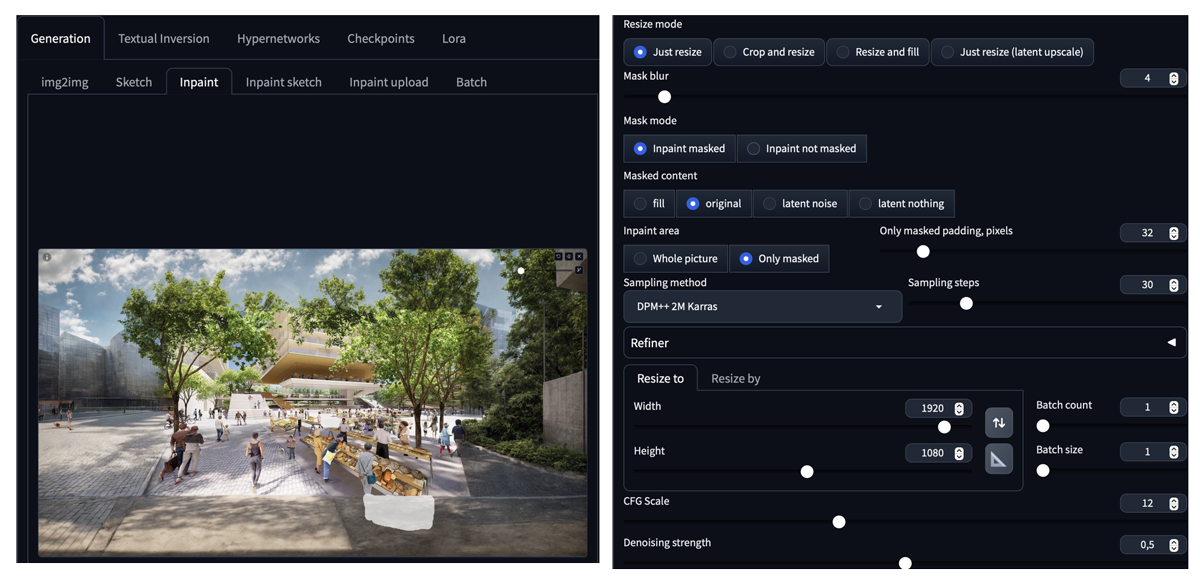
Il processo seguito per espandere le immagini è il seguente: utilizzando il modello inpaint di Control Net nella modalità di resize and fill, l'immagine è stata prima scalata orizzontalmente da 1024px a 1920px e poi anche verticalmente fino a raggiungere l'altezza di 1080px e le nuove parti sono state generate secondo il prompt fornito.
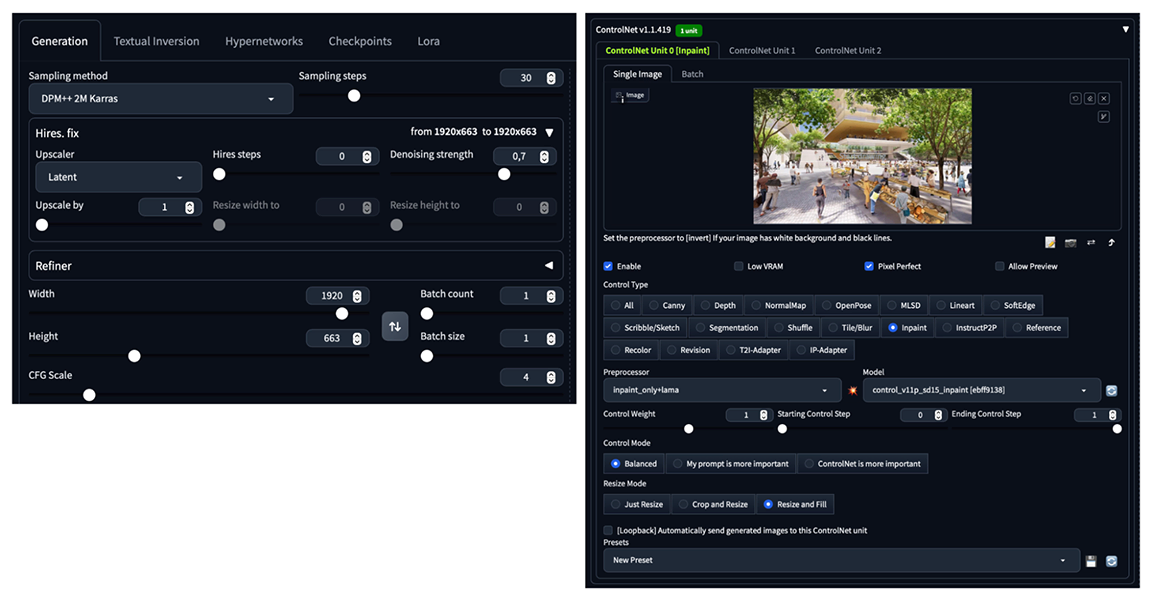
Infine, le immagini risultanti sono state perfezionate correggendo alcuni dettagli utilizzando la funzione inpaint della scheda img2img sempre all'interno di Stable Diffusion.